Publications
Major publications are listed below; for a complete publication list, please visit my Google Scholar profile.
2026
- ICLR 2026 (Oral)
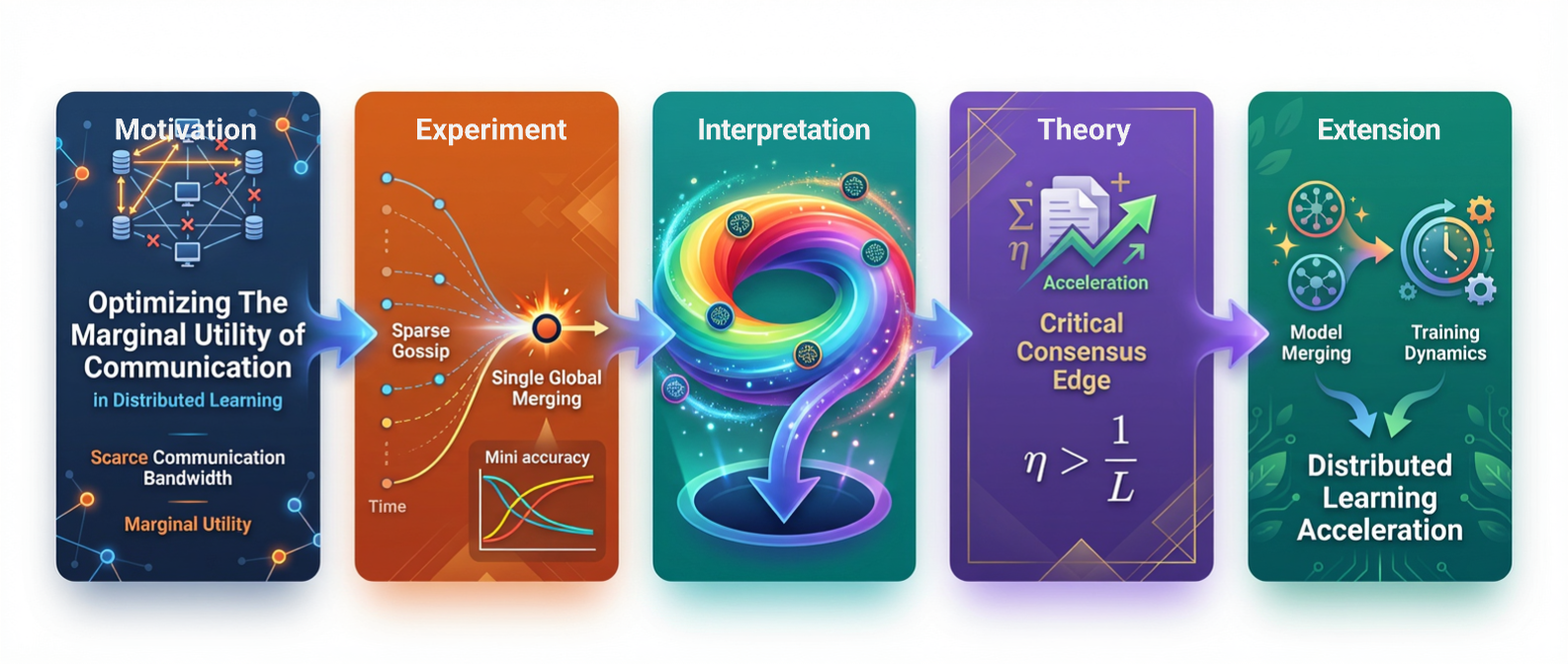 On The Surprising Effectiveness of a Single Global Merging in Decentralized LearningIn International Conference on Learning Representations, 2026
On The Surprising Effectiveness of a Single Global Merging in Decentralized LearningIn International Conference on Learning Representations, 2026
2025
- ICLR 2025
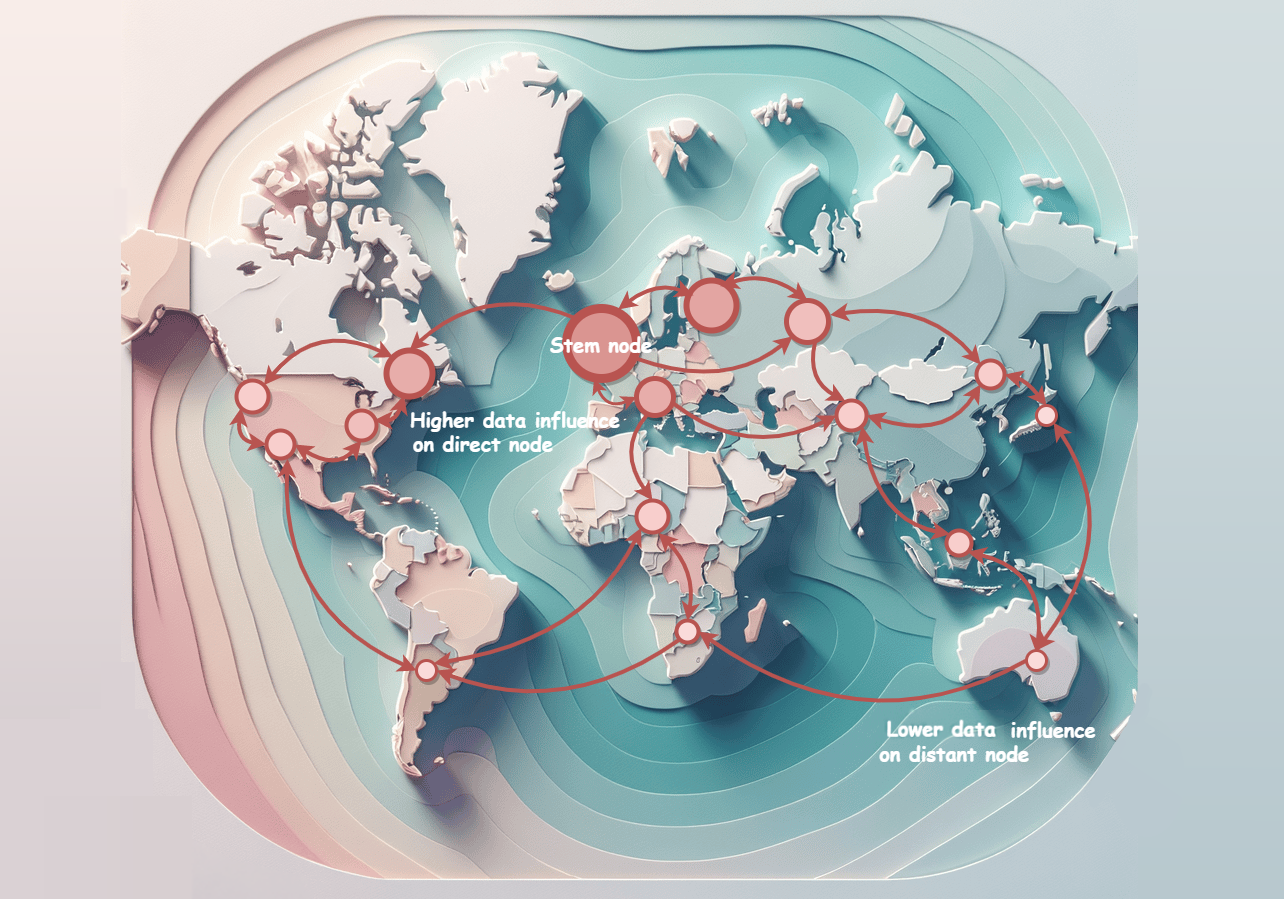 DICE: Data Influence Cascade in Decentralized LearningIn International Conference on Learning Representations, 2025
DICE: Data Influence Cascade in Decentralized LearningIn International Conference on Learning Representations, 2025
.png)